Giriş
Yüzlerce milyon domain veri noktası üzerinde analitik çalıştırdığınızda Elasticsearch sadece "arama" değildir; ürün ekipleri, analistler ve bazen ortak ekosistemler için üretim veri düzlemidir. Domainsbot tarafında Pandalytics (şirketin bugünkü adıyla Business Intelligence platformu) tam da bu dünyada: geniş mapping'ler, uzun süren sorgular ve Kibana'dan alınan dışa aktarımlar—yani demo boyutlarında değil, gerçek kullanıcı beklentilerinde yaşamak zorunda.
AWS üzerinde yönetilen bir Elasticsearch 7.x kurulumu ve yanında Elasticsearch 2.x mirası ile çalıştık. İş tek bir ticket değildi; önce istikrar, sonra raporlama hızı deseniydi ve rakamlar sunum slaydından çok saha notlarında duruyordu.
Sorun
Üç baskı aynı anda göründü.
Sorgu Zaman Aşımları
Kümede search.default_search_timeout 50 saniye idi. Birçok panel için idare eder; ama ağır aggregation'lar, büyük sonuç kümeleri ve analist beklentileri bir araya gelince kullanıcılar "yumuşak" bir hatayla değil, duvara çarpıyordu.
JVM Heap ve Circuit Breaker Baskısı
Data node'larda heap 24 GB olmasına rağmen, bir SRE'yi durduran log satırları vardı: circuit breaker hareketi, G1 ile baskı altında toplanma ve "önce/sonra" heap rakamları. Nisan 2023 tarihli örneklerde kümenin yoğun dönemlerde sınırda çalıştığını gösteren kayıtlar mevcuttu.
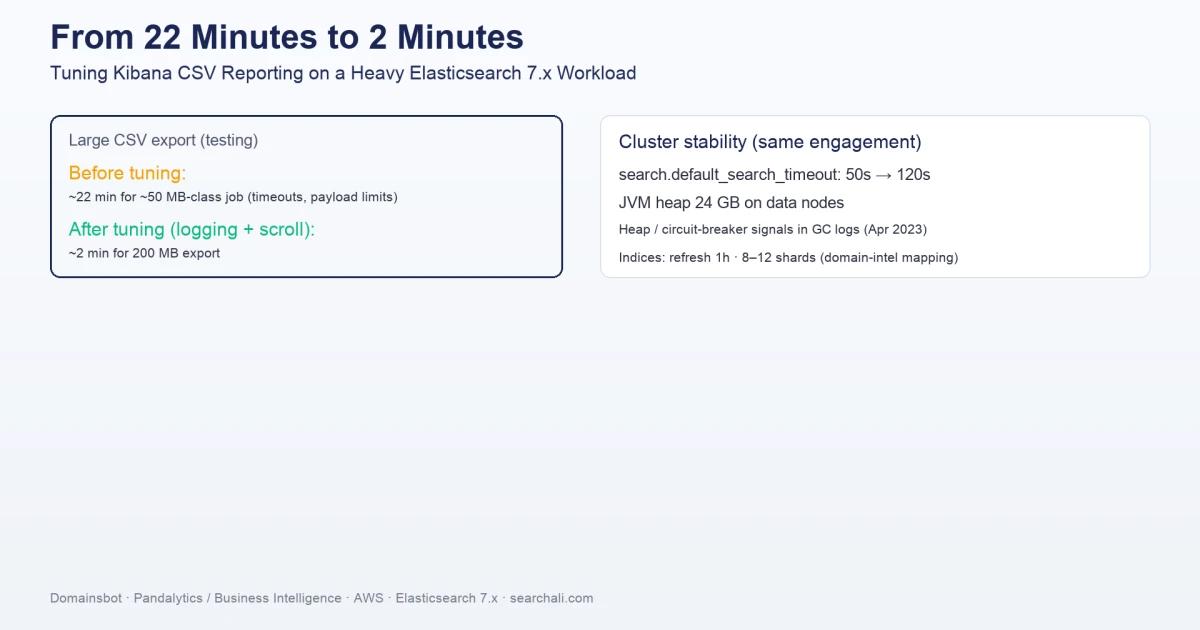
Ölçekte Kibana CSV Raporlama
Test notları acıyı açık yazıyordu: yaklaşık 50 MB sınıfı bir dışa aktarım, kuyruk zaman aşımı genişletilerek çalıştırılabildiğinde yaklaşık 22 dakika sürebiliyordu. Oysa beklenti 100–200 MB CSV yapılandırmalarına ve daha hızlı dönüşe kayıyordu. Varsayılan Kibana limitleri ve task-manager davranışı—zaman aşımı, event-loop uyarıları, "max size reached" tarzı kesilmeler—hikâyenin parçasıydı. Sorun çoğu zaman "Elasticsearch yavaş"tan çok raporlama hattı ve düğüm maliyeti gibi görünüyordu.
2023 başındaki toplantı notlarında ayrıca rol bazlı export beklentisi ve Kibana'nın indirme limitleriyle ilgili pratik sorular vardı; bu da sorunu yalnızca "parametre çekmek"ten çıkarıp güvenlik ve raporlama mimarisi seviyesine taşıyordu.
Teşhis
Veri Düzlemi ile Raporlama Düzlemini Ayırmak
Her zamanki gibi başladım: veri düzlemi sorunlarını raporlama düzlemi sorunlarından ayırdım.
Elasticsearch tarafında domain intelligence için indeks tasarımı bilinçli biçimde geniş: DNS, HTTP, WHOIS, SSL, iç içe konular ve geniş keyword/text yüzeyleri. Ortamda örnek indekslerde 8–12 birincil shard, bir replica ve bir saatlik refresh_interval vardı—toplu ingest için mantıklı; ama aramanın "hissi" ve tek bir export'un ne kadar iş yaydığı açısından anlamlı.
Kibana Deneylerinin Ortaya Koyduğu Şey
Kibana tarafında notlar deneyleri net yazıyordu: xpack.reporting.csv.maxSizeBytes artırmak, kuyruk zaman aşımı, scroll boyutu ve hatta Elasticsearch http.max_content_length değerini 100 MB'tan 1 GB'a çıkarmak—ki bu tek başına sıkışmayı çözmedi. Önemli bir ders: HTTP tavanını kaldırmak, CSV üretimini hızlandırmak değildir.
Testlerde kırılma noktası sıradan bir ayrıntıydı: logging.root.level → warn ve xpack.reporting.csv.scroll.size: 1500 birlikte, ağır işi kısa süreye indirdi. Aynı notlarda 200 MB'lık bir export bu kombinasyonla yaklaşık iki dakikada tamamlandı. Daha önce scroll 5000 ile 70.000 doküman yaklaşık dokuz dakika sürmüş; 5000'in 1500'ü her zaman yenmediği de kaydedilmiş. Task-manager için aşırı agresif ayarlar teoride cazip, pratikte Node event-loop baskısı altında geri teper—saha notlarında özellikle kötü fikir diye işaretlenmiş.
Çözüm
Elasticsearch'ü soyutlamada "optimize etmedik." Üç katmanı hizaladık.
Katman 1 — Arama Güvenilirliği
Uzun süren analist sorguları meşru olduğunda search.default_search_timeout değerini 50s'den 120s'ye taşıdık; sonsuz zaman aşımıyla maskelemek yerine yavaş sorguyu kaynağında ele aldık.
Katman 2 — Data-Node Sağlığı
24 GB heap'i gerçek GC ve circuit-breaker sinyalleriyle birlikte okuduk—yani shard sayısı ve sorgu şekillerinin raporlama sırasında tekrar tekrar allocation zıplamasına yol açmamasını sağladık.
Katman 3 — Raporlama Hızı
CSV üretimini Kibana ölçeklenebilirlik problemi olarak ele aldık: log seviyesi, scroll, kuyruk zaman aşımı ve gerektiğinde yatay Kibana veya ayrı raporlama node'ları. Elastic'in resmi Kibana production rehberi, tek instance darboğaza girdiğinde ayrı raporlama node'unun kalıcı çözüm olduğunu belgeliyor.
Ayrıca üretimde yaptığınız gibi operasyonel hijyeni doğruladık: task-manager sağlığı, Kibana durumu ve büyük export'larda Elasticsearch'ten önce devreye giren payload limitleri (server.maxPayloadBytes) gibi "sıkıcı ama gerçek" kısıtlar.
Kullanıcı gözünden bakınca: arama yüzdelikleri iyi görünürken raporun düşmesi yine de "sistem çöktü" hissi yaratır. Bu yüzden CSV hızını ürün kritik bir başarı ölçütü gibi ele aldık.
Sonuçlar
Proje Notlarından Gelen Rakamlar
Bunlar pazarlama benchmark'ı değil; proje notlarında duran rakamlar:
search.default_search_timeout: 50s → 120s- JVM heap: data node'larda 24 GB, Nisan 2023 loglarıyla ilişkilendirilen heap baskısı incelemeleri
- CSV raporlama (test):
- Doğru logging + scroll ayarı öncesi ~50 MB sınıfı iş için ~22 dakika
logging.root.level: warnvexpack.reporting.csv.scroll.size: 1500sonrası 200 MB export için ~2 dakika- 70.000 doküman için scroll denemelerinde ~9 dakika (1500 vs 5000 karşılaştırmaları notlarda)
Bu çiftler mükemmel "elma-elma" karşılaştırma değil; satır genişliği, filtre ve önbellek oynatır. Yine de baskın maliyetin her zaman Elasticsearch sorgu süresi olmadığını; Kibana'nın işi nasıl yürüttüğü ve nasıl logladığı olduğunu gösteren dürüst kanıtlar.
Öğrendiklerimiz
Bu Çalışmanın Bize Öğrettikleri
- Geniş, mapping ağırlıklı indeksler (DNS/WHOIS/konular) CSV export'un maliyet modelini değiştirir; shard sayısı ve scroll, yalnızca "sorgu hızı" kadar önemlidir.
http.max_content_lengthtek başına bu ortamda büyük CSV'yi açmadı; çözüm Kibana raporlama ayarları ve log yükündeydi.logging.root.level: warn, scroll ayarıyla birlikte beklenmedik kaldıraç oldu—CPU ve event-loop baskısı gerçek.- Task-manager uçlarını agresifleştirmek teoride cazip, pratikte riskli; Kibana ölçekleme rehberleri boşuna yazılmadı.
- Elasticsearch 2.x ile 7.x (AWS'te yönetilen) bir arada operasyonel yük getirir; uyumluluk ve geçişi arka plan riski değil ürün riski gibi ele alın.
Elasticsearch veya OpenSearch cluster'ınızı istikrara kavuşturmak için yardıma mı ihtiyacınız var? SearchAli, üretim Elastic Stack altyapıları için danışmanlık ve kurumsal eğitim sunuyor.