Giriş
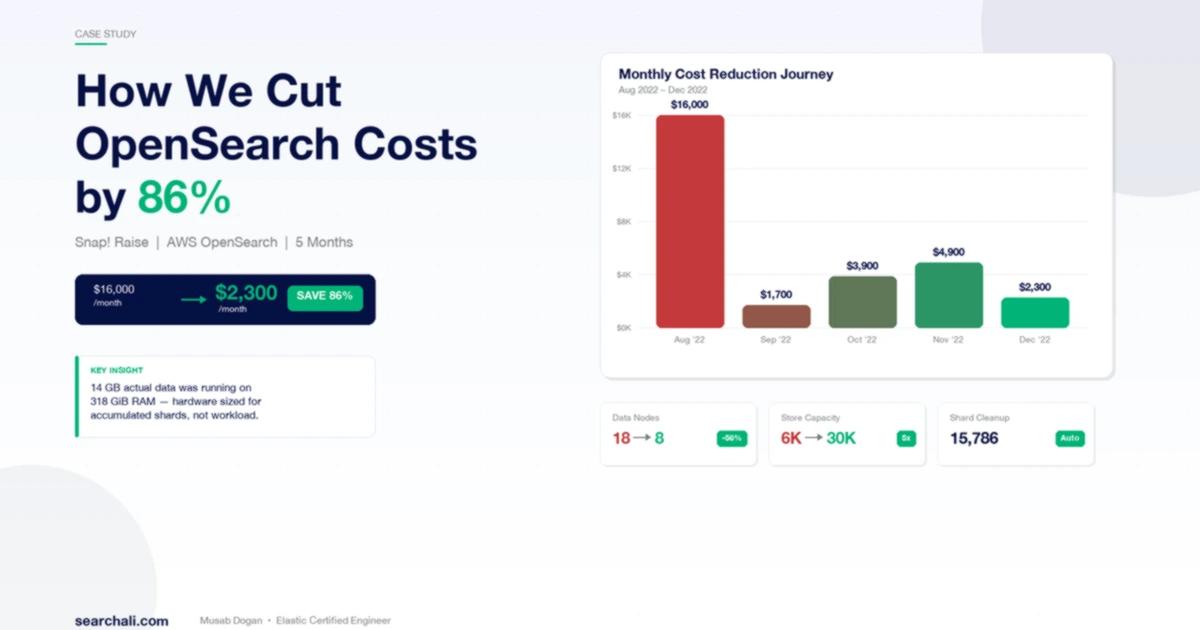
Bulut faturanız her ay artıyor ve neden olduğunu anlayamıyor musunuz? Snap! Raise tam da bu durumla geldi: aylık 16.000 dolarlık bir OpenSearch faturası, 18 data node, 15.786 shard — ama diskte duran gerçek veri yalnızca 14 GB. Beş ay içinde aynı cluster’ın aylık maliyetini 2.300$ seviyesine indirdik; toplam platform kapasitesini ise 6.000 mağazadan 30.000 mağazaya çıkardık.
Sorun
Snap! Raise, ABD genelinde 150.000’den fazla okul ve takıma dijital bağış toplama hizmeti sunan bir platform. Magento e-ticaret altyapısını kullanıyorlar ve her mağazanın ürün araması için ayrı bir AWS OpenSearch index’i bulunuyor.
- Aylık maliyet: 16.000$
- Cluster yapısı: 18 data node (r6g.xlarge, 32 GiB RAM) + 5 master node
- Toplam bellek: 318 GiB, toplam disk: 1.75 TB
- Shard sayısı: 15.786 (7.884 index)
- Gerçek disk kullanımı: 14 GB
1.75 TB ayrılmış disk alanına karşılık yalnızca 14 GB veri vardı. Cluster, ayrılan kapasitesinin %1’inden azını kullanırken fatura provision edilen kapasiteye göre oluşuyordu.
Teşhis
İlk adım olarak _cat/indices çıktısını boyuta göre sıraladım. Pattern hızla ortaya çıktı: Snap! Raise, mağaza-başına-index mimarisi kullanıyordu. Her katalog güncellemesinde yeni bir versiyonlu index oluşturuluyor, alias yeni index’e taşınıyor; ancak eski versiyonlar silinmiyordu.
Bu nedenle zamanla index sayısı katlandı. Sistemde 7.884 index vardı ama aktif olarak gereken sayı yaklaşık 1.740’tı. Her sahipsiz index iki shard (primary + replica) taşıyarak shard sayısını sessizce şişiriyordu.
AWS OpenSearch’te önerilen üst sınır yaklaşık 25 shard/GB RAM iken bu cluster yaklaşık 50 shard/GB seviyesindeydi. Sonuç: daha fazla node, daha yüksek maliyet, tekrar eden döngü.
Çözüm
Optimizasyonu beş ay boyunca üç aşamada uyguladım.
Aşama 1 — Doğru Boyutlandırma (Ağustos 2022)
1.740 aktif index ve 1 primary + 1 replica ile toplam shard ihtiyacı 3.480’di. 25 shard/GB kuralına göre minimum 139 GB RAM gerekiyordu. İki erişilebilirlik bölgesinde 3 adet r6g.xlarge node ile 192 GB RAM sağlandı.
Bu adımla maliyet 16.000$’dan 1.700$’a düştü (yaklaşık %89).
Aşama 2 — Kontrollü Büyüme (Eylül–Kasım 2022)
- Eylül: Maksimum mağaza sayısı 6.000’den 14.000’e çıktı, maliyet 3.900$/ay.
- Kasım: Maksimum mağaza sayısı 18.000’e çıktı, maliyet 4.900$/ay.
Bu aşamada zamanlanmış bir temizlik script’i devreye alındı. Script; alias’ı olmayan index’leri, sıfır dokümanlı index’leri ve aynı mağaza için duplike versiyonları tespit edip siliyordu.
Aşama 3 — Son Optimizasyon (Kasım–Aralık 2022)
Index yaşam döngüsü kontrol altına alındıktan sonra yük testleri yapıldı: tam reindex döngüsü, production hacminde sorgu trafiği, CPU/bellek/gecikme takibi.
Sonuç: aynı iş yükü daha az data node ile güvenle taşınabildi. Ek olarak her 10 dakikada shard sayısını kontrol eden ve eşik yaklaşınca Slack’e bildirim gönderen uyarılar kuruldu.
Sonuçlar
| Metrik | Önce | Sonra |
|---|---|---|
| prod1 aylık maliyet | 16.000$ | 2.300$ |
| Data node sayısı (prod1) | 18 | 8 |
| prod1 mağaza kapasitesi | 6.000 | 16.000 |
| Toplam platform kapasitesi | 6.000 | 30.000 |
| Maliyet düşüşü | — | %86 |
| Index yönetimi | Manuel | Otomatik temizlik + uyarı |
Üç cluster için toplam aylık maliyet yaklaşık 4.150$ seviyesine inerken toplam kapasite 30.000 mağazaya ulaştı.
Öğrendiklerimiz
- Index şişkinliği sessiz maliyet katilidir. Veri büyümesinden çok, sahipsiz index birikimi fatura patlatır.
- Shard/GB oranı kritik bir sınırdır. 25 shard/GB kuralı pratikte maliyet ve stabilite dengesini belirler.
- Otomatik oluşturulan index’ler otomatik silinmelidir. Lifecycle yönetimi yoksa maliyetler tekrar büyür.
- Node sayısını ölçümle doğrulayın. Varsayımla değil, yük testiyle karar verin.
- Proaktif izleme ciddi tasarruf sağlar. Basit shard uyarıları gereksiz provisioning’i önler.
Elasticsearch veya OpenSearch cluster optimizasyonu konusunda destek almak için searchali.com’u ziyaret edebilirsiniz.